W3C DOM Tree
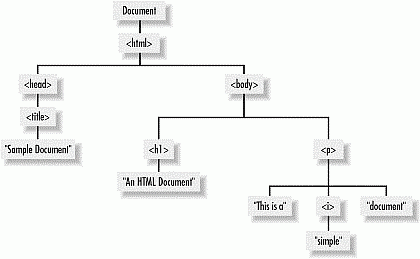
All web pages are stored as a tree structure in the browser.
A good analogy to use is that of a family tree.
The tree consists of a set of nodes starting with the root node Document.
Below the root node are the child nodes, tags at the same level are called siblings.
We can identify nodes using the tree structure and terms like child and sibling.
The h1 element is the body element's first child which we can write as body.firstChild
The p element can be referred to as the body.nextChild or the firstChild.nextSibling
There are two types of nodes, Text nodes and Element nodes.
- Text nodes contain plain text and have no child nodes
- Element nodes are the tags and may or may not have child nodes and attributes.
For example, <span id='fred'> is an element with an attribute id
Web browsers such as IE will take badly formed pages and try to 'fix' the tree structure by adding or removing nodes.
Which is why if you write a poorly structured page it may still render
correctly on screen.
Dynamically changing a web page is simply a question of adding, removing or changing tree nodes.